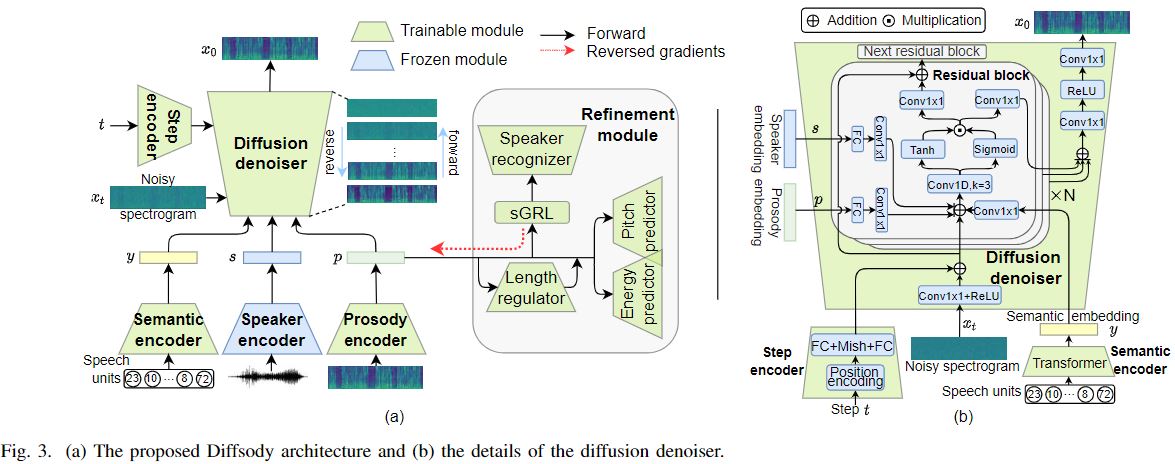
Model Architecture
Leyuan Qu1, Cornelius Weber2, Yingming Gao3, Taihao Li1 and Stefan Wermter2
1. Institute of Artificial Intelligence, Zhejiang Lab
2. Department of Informatics, University of Hamburg
3. School of Artificial Intelligence, Beijing University of Posts and Telecommunications
Prosody plays a fundamental role in human speech and communication, facilitating intelligibility and conveying emotional and cognitive states. Extracting accurate prosodic information from speech is vital for building assistive technology, such as controllable speech synthesis, speaking style transfer, and speech emotion recognition. However, it is challenging to disentangle speaker-independent prosodic representations since prosodic attributes, such as intonation, excessively entangle with speaker-specific attributes, e.g. pitch. In this paper, we propose a novel model, called Diffsody, to disentangle and refine prosody representations. (1) To disentangle prosodic representations, we leverage the expressive generative ability of a diffusion model by conditioning it on quantified semantic information and pretrained speaker embeddings. Additionally, a prosody encoder automatically learns prosody representations used for spectrogram reconstruction in an unsupervised fashion. (2) To refine and learn speaker-invariant prosody representations, a scheduled Gradient Reversal Layer (sGRL) is proposed and integrated into the prosody encoder of Diffsody. We thoroughly evaluate Diffsody through qualitative and quantitative means. t-SNE visualization and speaker verification experiments demonstrate the efficacy of the sGRL method in preventing speaker-specific information leakage. Experimental results on speaker-independent Speech Emotion Recognition (SER) and Automatic Depression Detection (ADD) tasks demonstrate that Diffsody can efficiently factorize speaker-independent prosody representations, resulting in a significant boost in SER and ADD. In addition, Diffsody synergistically integrates with the semantic representation model HuBERT, which leads to a discernibly elevated performance, outperforming contemporary methods in both SER and ADD tasks. Furthermore, the Diffsody model exhibits promising potential for various practical applications, such as voice or emotion conversion.
The diffusion denoiser reconstructs mel-scale spectrograms from Gaussian noises conditioned on semantic, speaker, and prosody information.

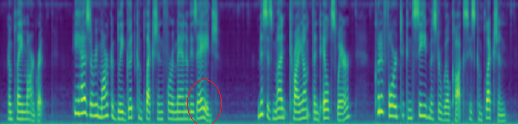
The refinement module helps the prosody encoder to capture and reconstruct more variants on prosody.
| Audio | Mel-spectrograms | |
|---|---|---|
| without Refinement Module |
 |
|
| with Refinement Module |
 |
|
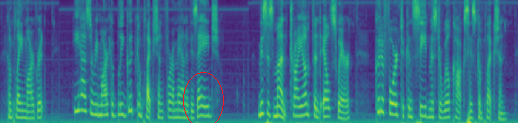
| Ground Truth |
 |
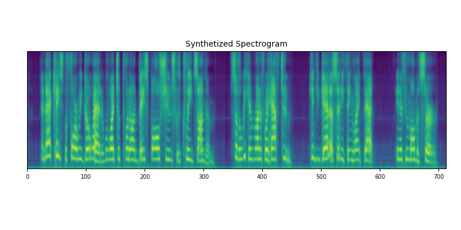
Diffsody can perform voice cloning by directly replacing the speaker encoder inputs with a differnet voice. Our proposed sGRL can effectively prevent speaker information leaky and guarantee the speaker information only learned from the speaker encoder.
| Original Audio | Reference Voice | |
|---|---|---|
| Method | Generated Audio | Generated Mel |
| without GRL/sGRL |
 |
|
| with GRL |
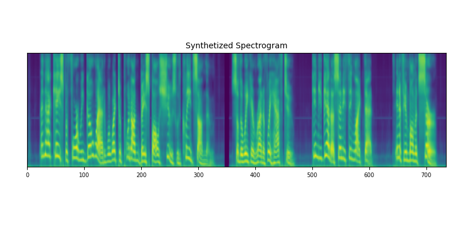 |
|
| with sGRL |
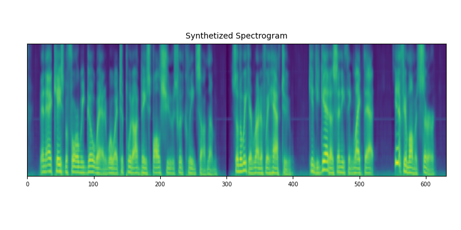 |
When representing style reference inputs to the prosody encoder, we can transfer the given styles to original speech while keeping the voice unchanged.
| Original Audio | Reference Style | Generated Audio |
|---|---|---|
Acknowledgement
This work was supported in part by the National Science and Technology Major Project of China (2021ZD0114303), in part by the Youth Foundation Project of Zhejiang Lab (K2023KH0AA01), and in part by the CML Project funded by the DFG.